Lower costs, equal performance: How to make AWS S3 Intelligent-Tiering your default storage class


Let’s talk about cloud storage – specifically, Amazon S3. Amazon S3 is one of the most reliable and widely used cloud storage services, but it’s also increasingly complex. The internet is littered with people getting surprisingly large storage bills because they didn’t optimize their storage or didn’t understand the cost model.
This is classic AWS — and not in a bad way. They launch powerful services that can be tremendously beneficial to businesses, but they don’t provide a lot of guidance on when/where/how to best use or configure them. Many of their products overlap, and they have been historically un-opinionated on the best way to combine and configure them, especially when it comes to cost. IT teams, for the most part, must navigate the resulting decision points on their own. S3 is no exception.
Fortunately, Amazon S3 includes a storage class called Intelligent-Tiering that can tackle the complexity for you. With S3 Intelligent-Tiering, your organization can save money without sacrificing performance. It’s a relatively simple switch that can make a serious impact on your budget.
A brief history of Amazon S3 Intelligent-Tiering
Amazon S3 (Simple Storage Service) is AWS’s foundational data storage layer. Amazon launched it in 2006 as a simple and scalable business storage solution. It allowed developers to store and retrieve large amounts of data, such as files and images, via an API. Amazon S3 now stores over 100 trillion objects.
Amazon S3 uses storage classes to help users effectively manage their data. A storage class is a set of performance criteria for how the data is stored. Each storage class is optimized for a particular set of requirements related to data redundancy, data access speed, and cost.
The S3 Intelligent-Tiering storage class, announced at AWS reInvent 2018, offers a unique approach to storage cost management. It works by monitoring data access patterns and moving data to the most cost-effective access tier based on these patterns. With S3 Intelligent-Tiering (done right), users can save money on data storage costs without sacrificing performance or having to write, maintain, and implement their own data storage optimization layer.
S3 Intelligent-Tiering access tiers = automatic cost optimization
Prior to S3 Intelligent-Tiering, the myriad of storage classes theoretically made it easier to manage costs, but required expert knowledge (not to mention time) to use correctly. To realize optimal costs across the storage classes, you need to either monitor or forecast the requirements of each object across your S3 buckets. Some storage classes, such as Glacier, have substantial costs associated with data retrieval, particularly if you need very quick access.
Users, understandably, found this confusing.

Intelligent-Tiering changed that. It initially launched with two access tiers, Frequent Access and Infrequent Access (IA). An access tier is a categorization of data based on when it was last accessed. We can think of access tiers as the dynamically switchable storage classes available to S3 Intelligent-Tiering.
Access tiers enable Intelligent-Tiering to automatically optimize costs by dynamically shifting objects between them according to data usage patterns. The different access tiers have the same latency and throughput capabilities but are optimized for different access patterns. Frequent Access (FA) is optimized for, as you might guess, Frequent Access. Objects begin in the FA tier and, after 30 days, are moved to the Infrequent Access (IA) tier, which has reduced storage costs.
By automatically moving data to the most cost-effective access tier, Intelligent-Tiering can help businesses save a significant amount of money on storage costs without impacting performance. Most importantly, S3 Intelligent-Tiering allows AWS to optimize how data is stored while maintaining performance guarantees. This approach lets AWS continuously innovate through additional access tiers, faster movement of data between the tiers, and more intelligent data access monitoring.
More access tiers, more opportunities to optimize and save
AWS added two additional access tiers in November 2020: the Archive Access (AA) and Deep Archive Access (DAA) tiers. These tiers enabled further optimizations by allowing data not accessed after 90 or 180 days to be moved into S3 Glacier or Glacier Deep Archive storage classes. They are significantly cheaper than FA and IA, but they come with a large latency penalty. It can take up to 5 hours to retrieve data from AA, and up to 12 hours from DAA. This change is significant; it would require significant changes to downstream applications to access data in such a delayed, asynchronous manner.
In November 2021, AWS Announced the Glacier Instant Retrieval storage class. At the same time, they also introduced the Archive Instant Access (AIA) access tier for S3 Intelligent-Tiering. Data stored by S3 Intelligent-Tiering is stored at the same price as if it were stored manually in an S3 Bucket with the Glacier Instant Retrieval (GIR) storage class. It provides access to S3 objects within milliseconds but is designed for infrequently accessed data.
Data lakes, analytics, medical records, and media content often fall into this category. Access is infrequent, but when it is requested, it is needed immediately. The downside to GIR vs S3 Standard is that requests into GIR are 4x-25x more expensive relative to S3 standard. With S3 Intelligent-Tiering, if your data is in the AIA tier, then the request cost is the same as S3 Standard, but the storage cost is the same low cost as GIR. It is effectively a win-win.
In short, by adding Archive Instant Access to S3 Intelligent-Tiering, Amazon gave users the benefits of the Glacier Instant Access storage class without paying the additional request premium for data in the Glacier Instant Retrieval storage class. Can’t complain about that.
Crunching the numbers: How to cut your AWS storage costs in half
When configured properly (we’ll get to that), S3 Intelligent-Tiering can deliver large cost savings with no impact on performance. Most data has unknown access patterns, and Intelligent-Tiering enables cost optimization without needing to know your access patterns in advance. Many AWS customers are using Intelligent-Tiering as their default storage class for S3 Buckets.
We can hear the question now: but wait! If it’s so effective, why doesn’t AWS enable Intelligent-Tiering by default?
The answer: AWS adds features iteratively but the defaults almost always remain the same. Even if S3 Standard is a suboptimal choice for cost savings, it is still the default S3 Bucket storage class. There are many other parts of the AWS ecosystem that operate similarly, like EBS Volume Configuration (which CloudFix can also help optimize.)
Let’s get into numbers.
The costs of data storage in S3 vary from region to region and over time, but as of January 2023, for the us-east-1 region, the prices are as follows.
|
S3 Standard |
||
|
First 50 TB / Month |
$0.023 per GB |
|
|
Next 450 TB / Month |
$0.022 per GB |
|
|
Over 500 TB / Month |
$0.021 per GB |
|
|
S3 Intelligent-Tiering – Automatic cost savings for data with unknown or changing access patterns |
Relative to S3 Standard |
|
|
Monitoring and Automation, All Storage / Month (Objects > 128 KB) |
$0.0025 per 1,000 objects |
|
|
Frequent Access Tier, First 50 TB / Month |
$0.023 per GB |
100% |
|
Frequent Access Tier, Next 450 TB / Month |
$0.022 per GB |
100% |
|
Frequent Access Tier, Over 500 TB / Month |
$0.021 per GB |
100% |
|
Infrequent Access Tier, All Storage / Month |
$0.0125 per GB |
56.8% |
|
Archive Instant Access Tier, All Storage / Month |
$0.004 per GB |
18.2% |
As you can see, S3 Intelligent-Tiering gives you savings if the monitoring charge is less than the cost savings from the lower tiers. The monitoring charge is $0.0025 per 1000 objects. Unless you are storing many tiny objects, your monitoring cost will be very small relative to storage costs.
Note that the Frequent Access tier of S3 Intelligent-Tiering is equivalent in price and performance to S3 Standard. The Infrequent Access and Archive Instance Access tiers are equivalent to S3 Standard in performance, but for a fraction of the cost. All objects in S3 Intelligent-Tiering also incur a monitoring charge, as listed in the table.
Let’s do some “back of the envelope” calculations. Assume that we have objects that are 1MB each. It would cost $0.0025 to monitor these 1000 objects. Then, if all of the objects are stored in S3 Standard, the monthly storage cost would be $0.023. If the objects are stored in Intelligent-Tiering, then the calculation depends on the distribution of the objects across the access tiers.
During our time monitoring over 40,000 AWS accounts, including many thousands of S3 Buckets, we have found that the steady-state distribution objects into access tiers tend to look like this:
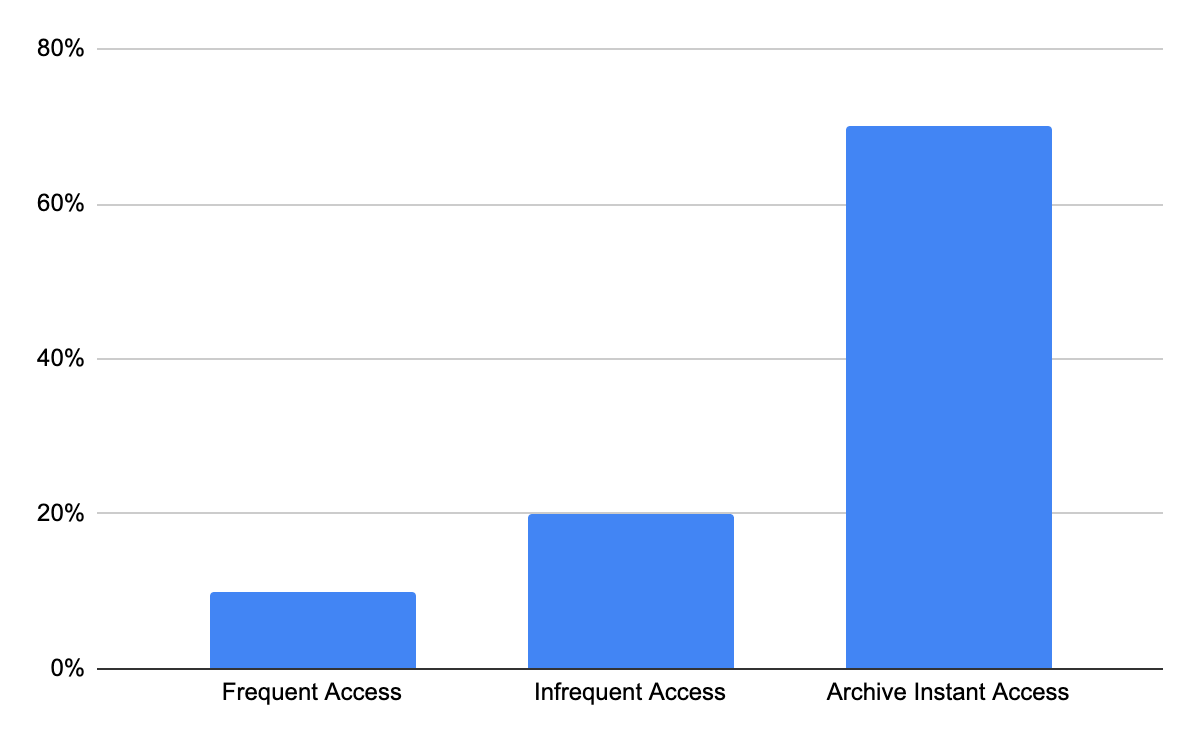
Let’s apply this distribution to the pricing table.
|
Distribution |
Num Objects |
Per GB Cost |
Monitoring |
Monthly Cost |
|
|
S3 Standard |
100% |
1000 |
$0.023 |
$0.0000 |
$0.0230 |
|
S3 Intelligent-Tiering |
$0.0101 |
||||
|
– Frequent Access (FA) |
10% |
100 |
$0.023 |
$0.0003 |
$0.0026 |
|
– Infrequent Access (IA) |
20% |
200 |
$0.013 |
$0.0005 |
$0.0030 |
|
– Archive Instant Access (AIA) |
70% |
700 |
$0.004 |
$0.0018 |
$0.0046 |
|
Relative Cost |
43.91% |
Scanning this table, we can see the cost of storing a set of objects in S3 Standard vs. the instant access (FA, IA, AIA) tiers of S3 Intelligent-Tiering. The latter option costs 43.9% of storing the same data using S3 Standard, and this includes the monitoring overhead.
In other words, AWS will monitor your data, optimize the data’s distribution into access tiers, move the data when access patterns change, and guarantee equivalent performance to S3 Standard, for often less than half of the price. This is why we are such advocates for S3 Intelligent-Tiering (and AWS superfans in general.)
Your savings will vary depending on data access patterns. The worst case would be if the vast majority of your data are accessed frequently, and/or your data is entirely composed of very small ( <128kb ) files. Happily, this rarely happens; we’ve never seen it in the wild. It’s actually the opposite: in nearly every situation we have encountered, S3 Intelligent-Tiering has been a source of large cost savings.
Our advice: Enable Intelligent-Tiering, but skip the Glacier-based tiers
At CloudFix, we have monitored and optimized tens of thousands of AWS accounts. Based on that experience, we believe that the best tradeoff between cost savings and complexity is to enable S3 Intelligent-Tiering, but only across the instant access tiers. In other words, enable the access tiers which maintain low latency access and do not opt in to the Glacier-based tiers.
Why? It’s true that the cost savings with the Glacier-based tiers are extremely enticing, but they don’t always play out how you might think.
On a per GB basis, the Deep Archive Tier costs 25% of the Archive Instant Access tier. However, the Glacier-based tiers are not like the Frequent, Infrequent, or Archive Instant Access tiers. Deep Archive uses the Glacier Deep Archive class. In order to access files from Glacier Deep Archive, the object needs to be “Restored”.
When data is “Restored” from the archive, that data must be pulled from a “vault”. This can take up to 12 hours. As mentioned earlier, orchestrating this process will require modifications to your code. You will need to account for the fact that some data may be in Glacier, and then decide how to handle this programmatically. The downstream users of your code will need to modify algorithms and user interfaces.
This engineering effort will not, in most cases, be worth the potential savings. If your organization is storing large volumes of data for archival purposes, such as for backup or compliance, this can be done by explicitly using Deep Glacier in a different S3 Bucket. With the release of the Archive Instant Access access tier, you get all of the benefits of Glacier Instant Retrieval without locking your data into that storage class.
How to manually enable S3 Intelligent-Tiering with the AWS Management Console and AWS CLI
Ready to reduce costs with S3 Intelligent-Tiering? The process is relatively straightforward. As usual, when you need to make a change to your AWS configuration, the go-to tools are the Management Console and the AWS CLI.
AWS Management Console
To change existing objects to use S3 Intelligent-Tiering, you can browse to those objects within the S3 portion of the management console. Select them, choose Edit: storage class, and choose S3 Intelligent Tiering.
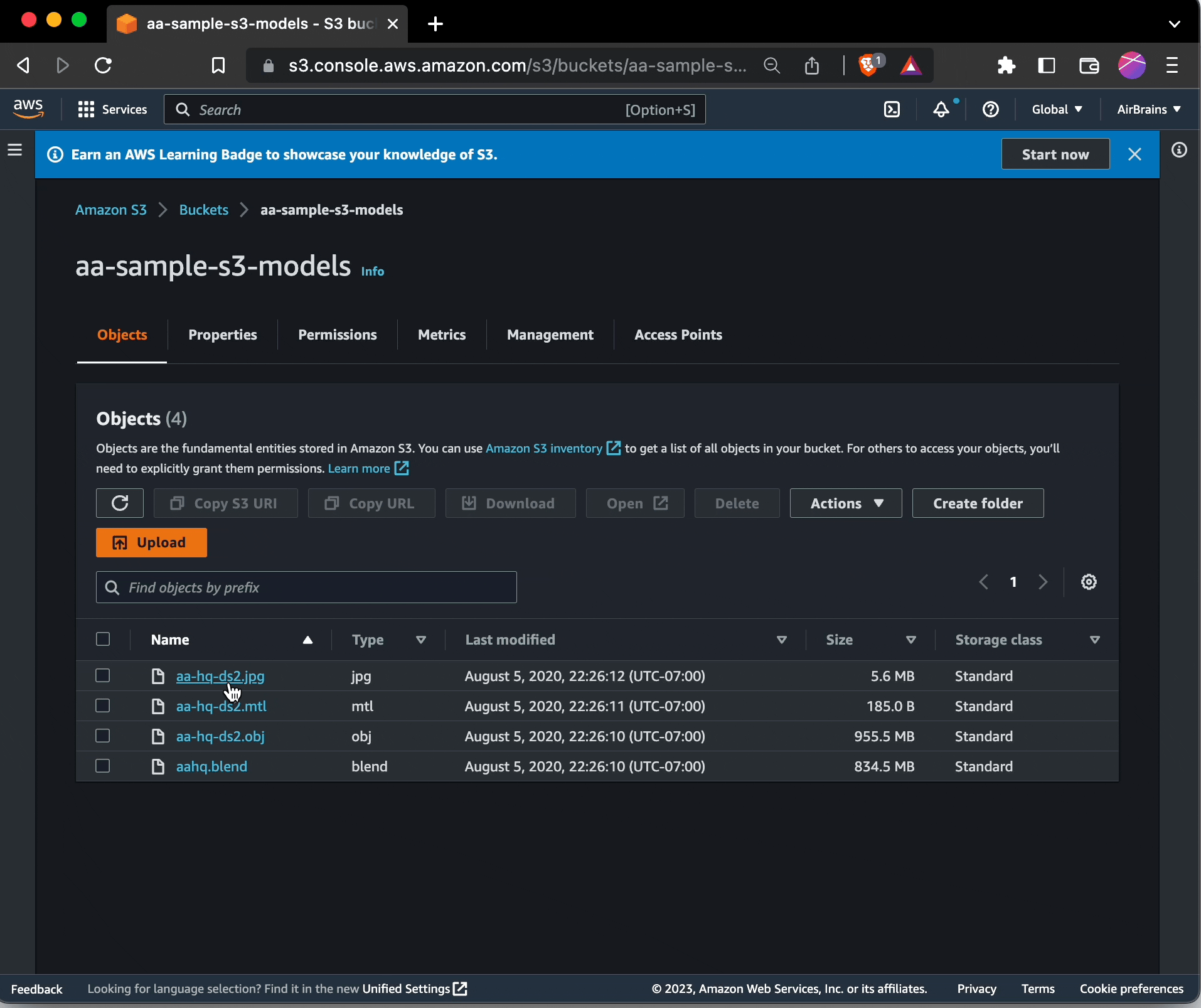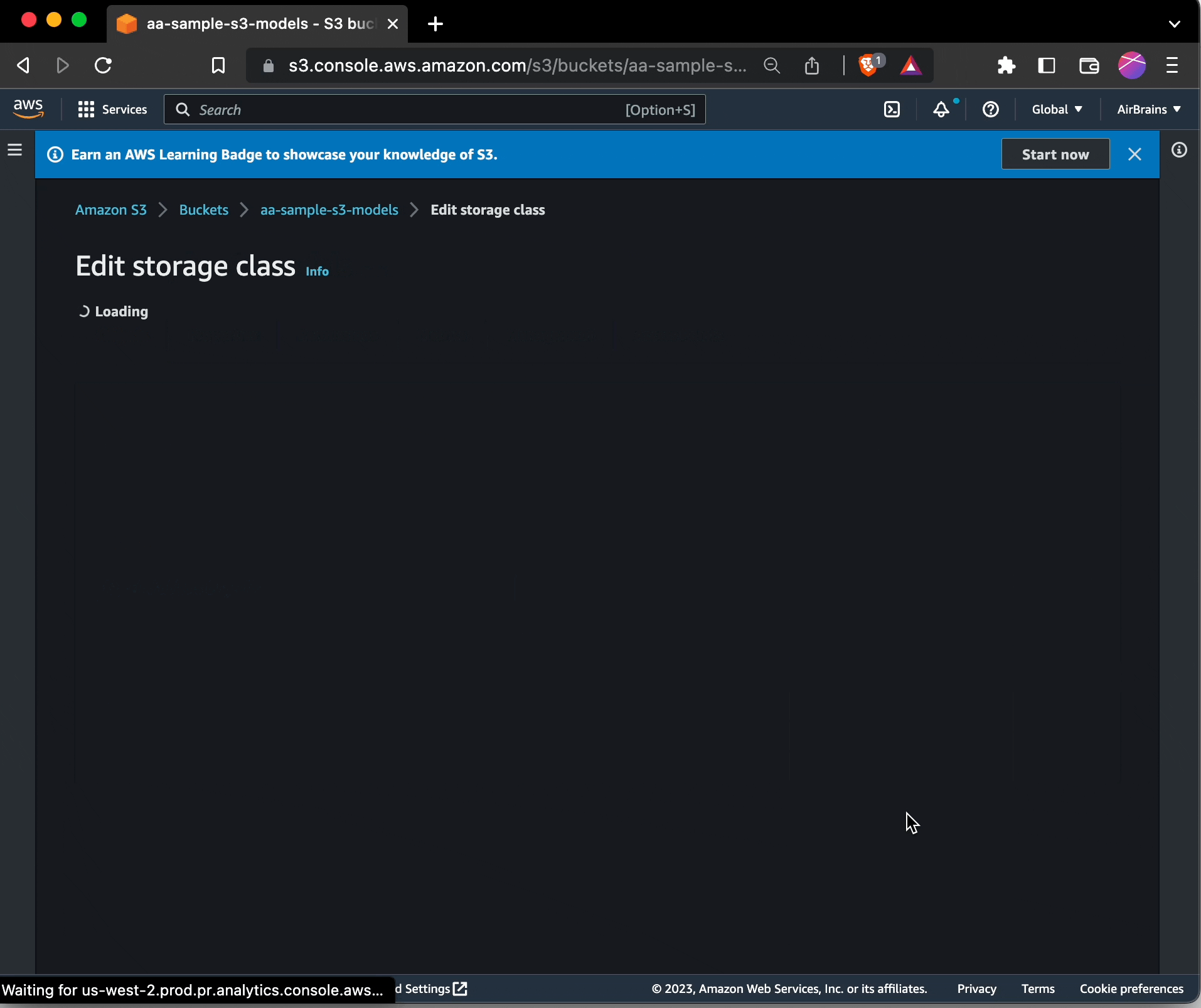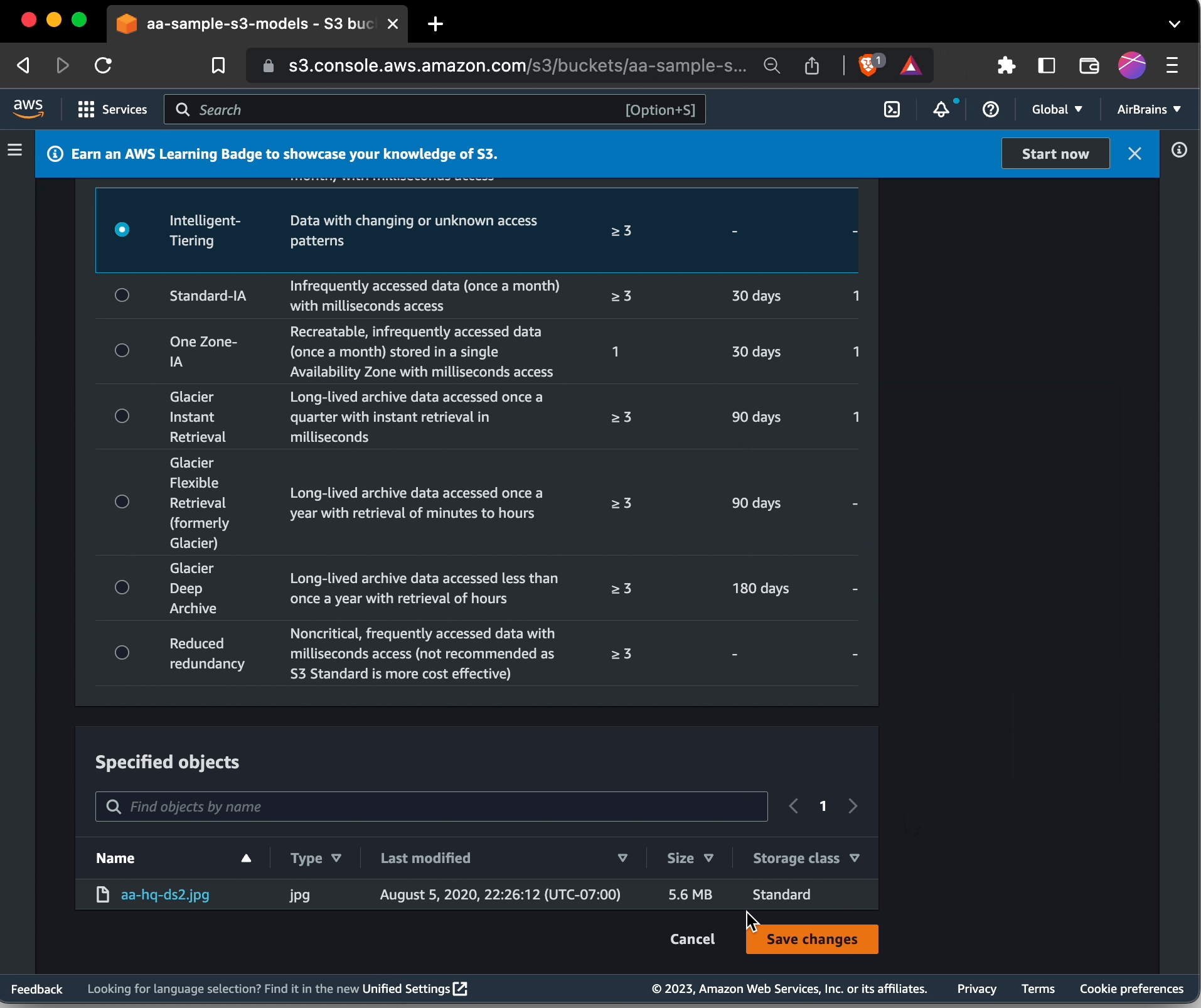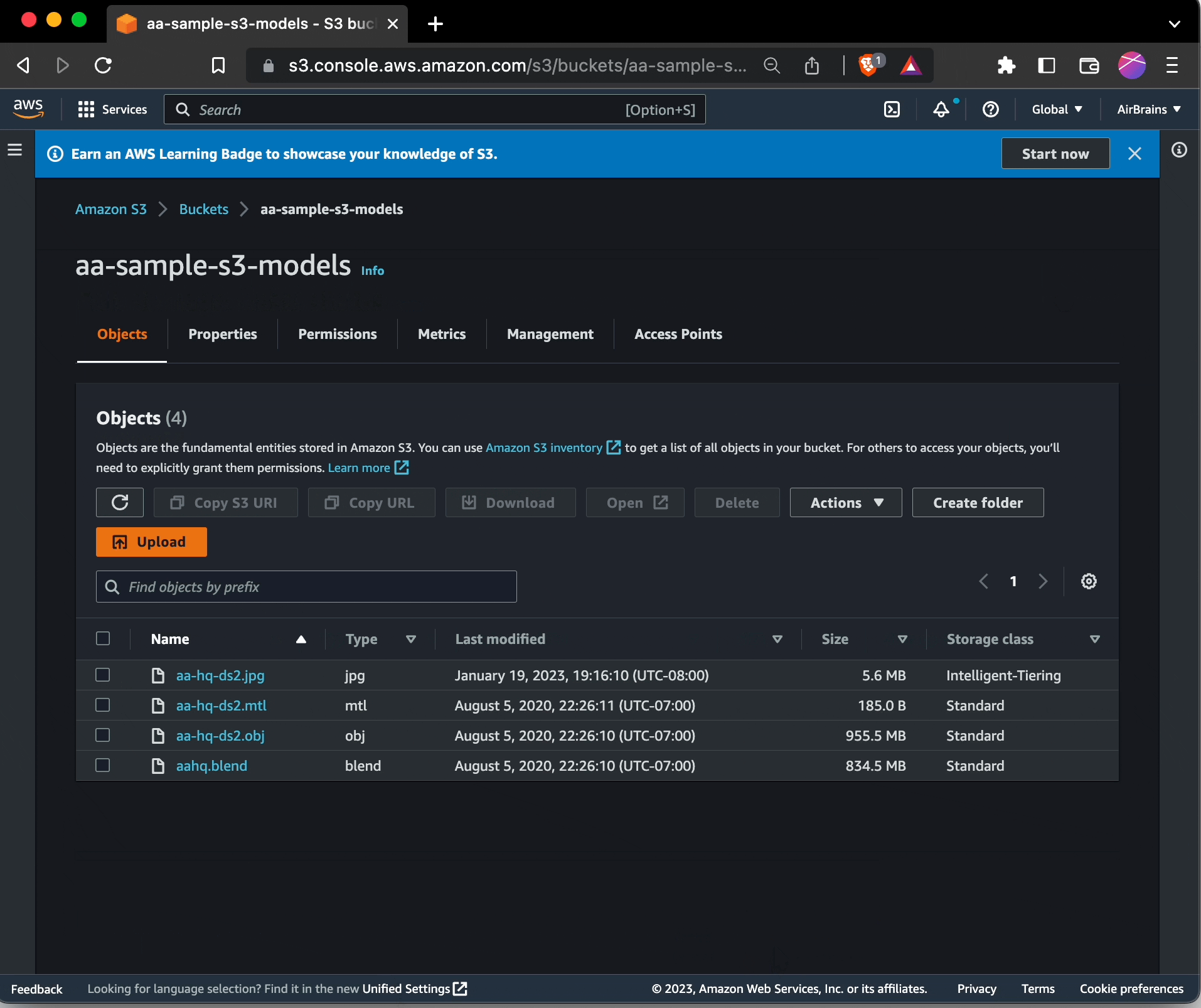
Needless to say, doing this for many buckets would be beyond extremely tedious.
AWS S3 CLI
To convert all objects in a particular bucket to Intelligent-Tiering, you can use a recursive copy operation.
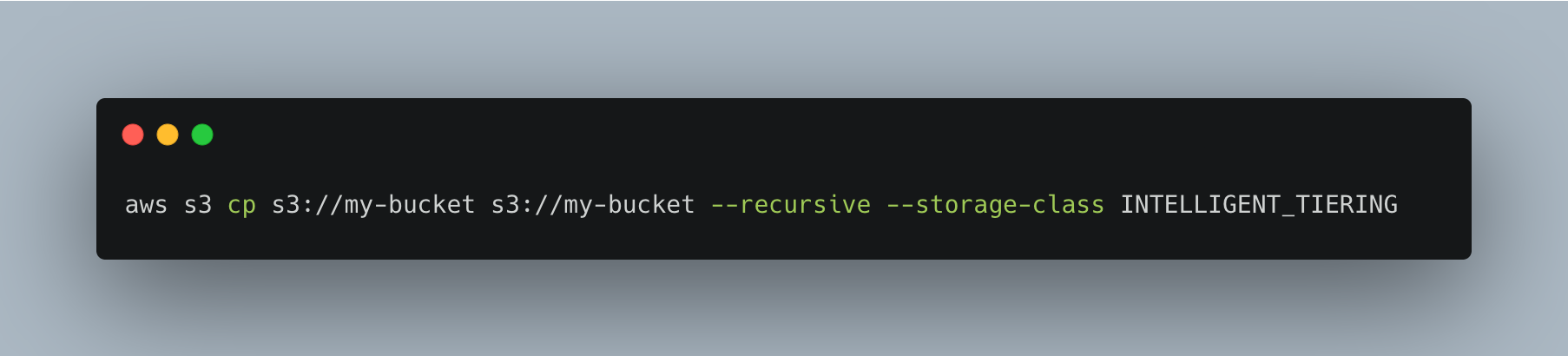
This code snippet only provides the “inner loop.” To do this across all of your buckets, and across all of your accounts, you would need to write the necessary bash scripts. Also, you would need to write a specific exclusion list to skip buckets or objects where S3 Intelligent-Tiering does not make sense.
Creating a bucket policy
To enforce S3 Intelligent-Tiering for all objects within a bucket, you can use a bucket policy.
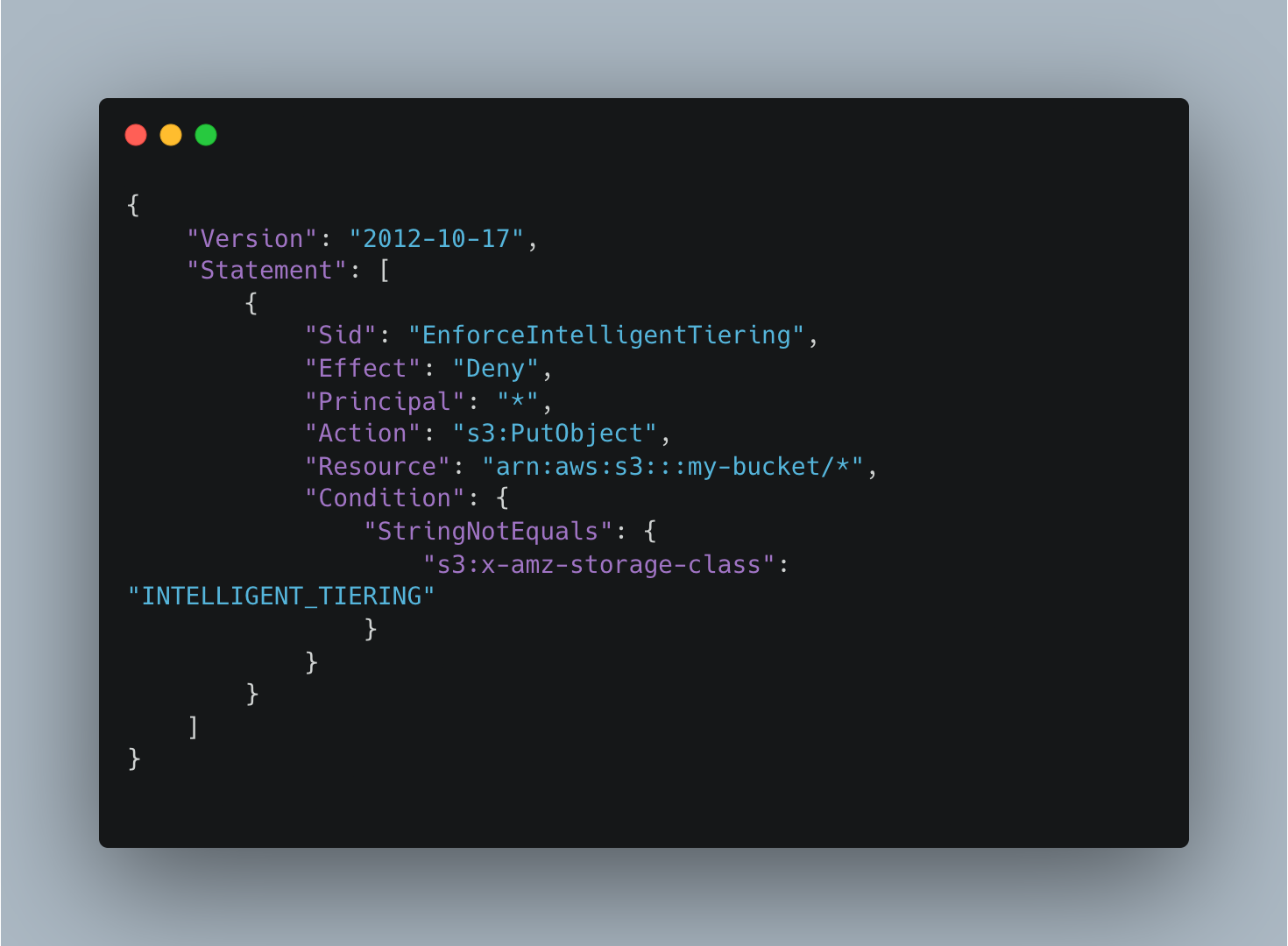
You can enforce a bucket policy using the AWS CLI or the AWS Management Console. In the AWS Management Console, navigate to the S3 service, select the bucket you want to apply the policy to, then click on “Permissions” and “Bucket Policy.” Then, paste the policy into the editor and save the changes. Using the CLI, save the above file as a JSON and then issue the following command:
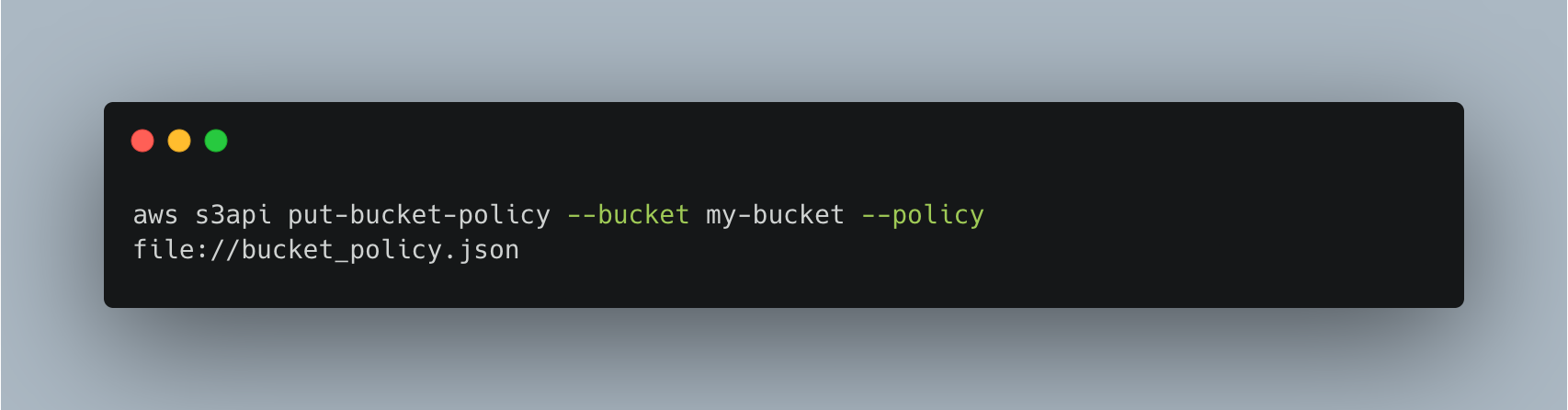
To validate that the policy has been applied, query the bucket’s policy:
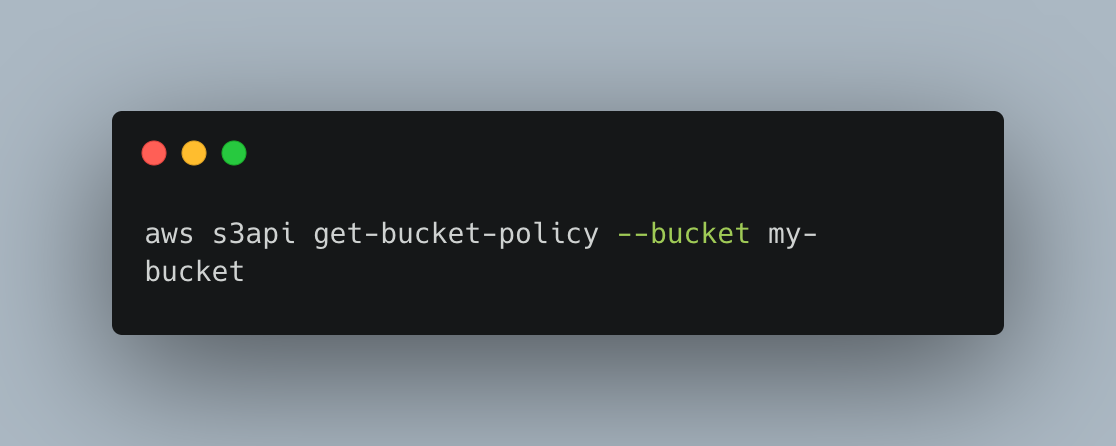
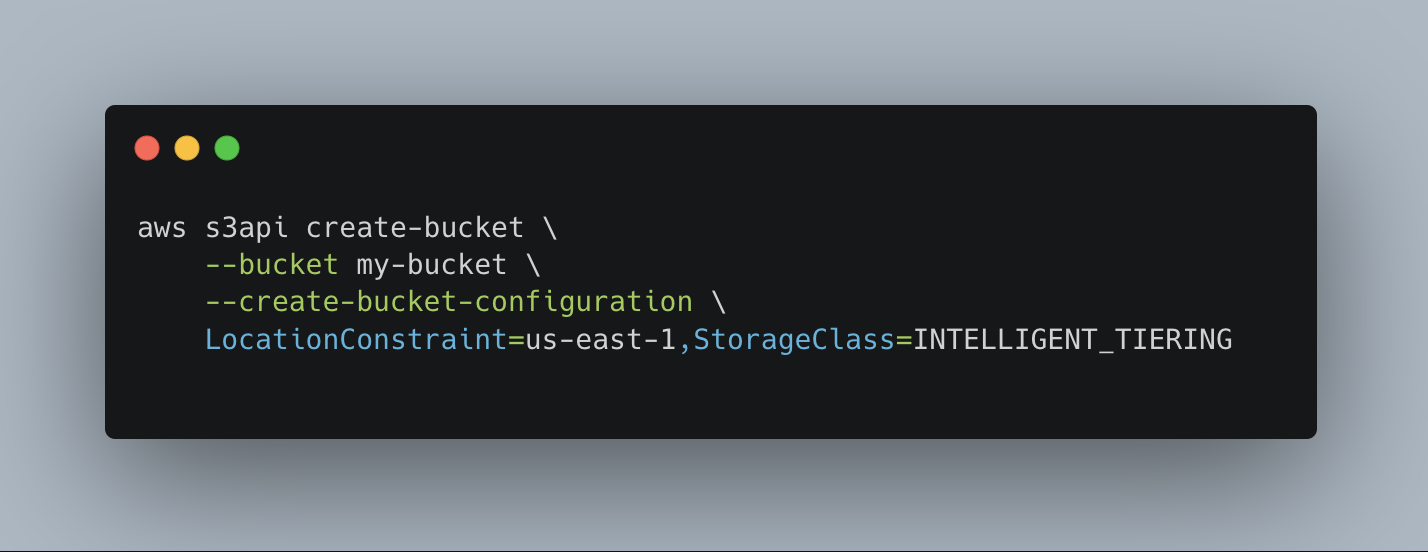
For new buckets, you should set the default storage class to Intelligent-Tiering. This can be done using the CLI with the following command:
CloudFix: the simple, secure way to switch to S3 Intelligent-Tiering
It’s reasonably straightforward to enable S3 Intelligent-Tiering via the AWS Management Console or API. The challenge isn’t doing it once, when you’re dealing with a finite amount of objects at one point in time. Where it gets tricky is enforcing Intelligent-Tiering across all accounts and for buckets that have yet to be created.
The solution: let CloudFix do the heavy lifting for you – not just once, but on an ongoing basis. Our Intelligent-Tiering “finder” and “fixer” continuously monitor your accounts, check the configuration of your S3 Buckets, and generate Change Manager actions which can be inspected and implemented in one click. Using CloudFix, S3 Intelligent-Tiering can be enabled and configured to deliver substantial cost savings with zero impact on performance, all with no changes needed to your application.
CloudFix solves the challenge of keeping up with your always-evolving AWS footprint. It ensures that as you continue to accumulate data, you are paying the optimal costs for that data while maintaining millisecond access times. We call it nonstop savings – and it doesn’t stop with S3 Intelligent-Tiering. CloudFix runs these types of “fixes” across your AWS infrastructure to reduce costs easily and automatically.
Find out how much your organization can save with a free, secure CloudFix savings assessment. You’ll see precisely how much you’re overspending by not leveraging S3 Intelligent-Tiering – and how CloudFix can put that money and more back in your budget.